

AWS Glue now supports streaming ETL. This feature makes it easy to set up continuous ingestion pipelines that prepare streaming data on the fly and make it available for analysis in seconds. Streaming ETL jobs in AWS Glue can consume data from streaming sources likes Amazon Kinesis and Apache Kafka, clean and transform those data streams in-flight, and continuously load the results into Amazon S3 data lakes, data warehouses, or other data stores. Customers can use this feature to process event data like IoT event streams, clickstreams, and network logs. Customers who want to use Teradata Vantage to analyze the data they stream from various sources will need to rely on AWS Glue custom database connectors.
Amazon Kinesis Data Streams (KDS) is a massively scalable and durable real-time data streaming service. KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources such as website clickstreams, database event streams, financial transactions, social media feeds, IT logs, and location-tracking events. The data collected is available in milliseconds to enable real-time analytics use cases such as real-time dashboards, real-time anomaly detection, dynamic pricing, and more.
Teradata is an AWS Partner Network (APN) Advanced Technology Partner specializing in cloud analytics, and has experience using these custom database connectors.
In this post, we provide step-by-step instructions to show you how to set up Vantage and author AWS Glue Streaming ETL jobs to stream data into Vantage from Amazon Kinesis and visualize the data.
About Teradata Vantage
Teradata Vantage combines traditional SQL capabilities with machine learning (ML) analytics to unify analytics, data lakes, and data warehouses in the cloud.
Vantage combines descriptive, predictive, prescriptive analytics, autonomous decision-making, ML functions, and visualization tools into a unified, integrated platform that uncovers real-time business intelligence at scale, no matter where the data resides.
Vantage enables companies to start small and elastically scale compute or storage, paying only for what they use, harnessing low-cost object stores and integrating their analytic workloads.
Vantage supports R, Python, Teradata Studio, and any other SQL-based tools. You can deploy Vantage across public clouds, on-premises, on optimized or commodity infrastructure, or as-a-service.
Teradata has decades of experience building and helping customers deploy Massively Parallel Processing (MPP) analytic databases. These solve large business challenges involving massive size, significant concurrent usage, and strict performance requirements that other technologies can’t solve.
About AWS Glue Streaming ETL
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. You can create and run an ETL job with a few clicks in the AWS Management Console.
AWS Glue now supports streaming ETL. This feature makes it easy to set up continuous ingestion pipelines that prepare streaming data on the fly and make it available for analysis in seconds. Streaming ETL jobs in AWS Glue run on the Apache Spark Structured Streaming engine, so customers can use them to enrich, aggregate, and combine streaming data, as well as to run a variety of complex analytics and machine learning operations.
Previously, you had to manually construct and stitch together stream handling and monitoring systems to build streaming data ingestion pipelines. Streaming ETL jobs in AWS Glue leverage AWS Glue’s serverless infrastructure to simplify resource management, optimize cost, and enable you to set up continuous ingestion pipelines without writing code - reducing average implementation time from months to days.
Using AWS Glue to Stream Data to Teradata Vantage
The following architecture illustrates the flow of data from Amazon Kinesis, through which it is streamed by AWS Glue to Teradata Vantage where it’s analyzed, and finally to Amazon QuickSight, where it’s displayed. In this tutorial we will be using a simple Lambda function to stimulate a streaming source.

Prerequisites
To use AWS Glue Streaming ETL with Teradata Vantage, first ensure you’ve met these prerequisites:
- You need an Amazon Elastic Compute Cloud (Amazon EC2) key pair to log into virtual machines. If you don’t already have one you wish to use, create a new one. In the following procedure, let’s name our key pair Teradata.pem and download it to your local machine.
- Create an Amazon QuickSight account, which requires a subscription.
Procedure
Once you have met the prerequisites, follow these steps:
- Subscribe to the Teradata Vantage Developer Edition. (This procedure also works with Vantage delivered as-a-service.)
- Launch an AWS CloudFormation stack to deploy Teradata Vantage and other required resources.
- Create a user and read/write database in Teradata Vantage.
- Use AWS Glue console to create Kinesis Table.
- Author Glue Streaming ETL job to start streaming.
- Use Amazon QuickSight to visualize data loaded to Teradata Vantage.
- Clean up.
Step 1: Subscribe to Teradata Vantage Developer Edition
Follow these steps to subscribe to Teradata Vantage Developer:
- Log into your AWS account.
- Visit the AWS Marketplace listing for Teradata Vantage Developer (Free, DIY).
- Select Continue to Subscribe in the top right corner.
- Select Accept Terms.
Once selected, you have agreed to the terms and can use this AWS Marketplace software in your account.
Step 2: Launch an AWS CloudFormation Stack to Deploy Vantage
AWS CloudFormation provides a common language for you to model and provision AWS and third-party application resources in your cloud environment. To deploy Vantage, follow these steps:
Click Launch Stack to deploy the Teradata Vantage Developer Edition along with all the resources required for completing this tutorial.
.png?origin=fd "aws-glue-streaming-picture1-(1).png")
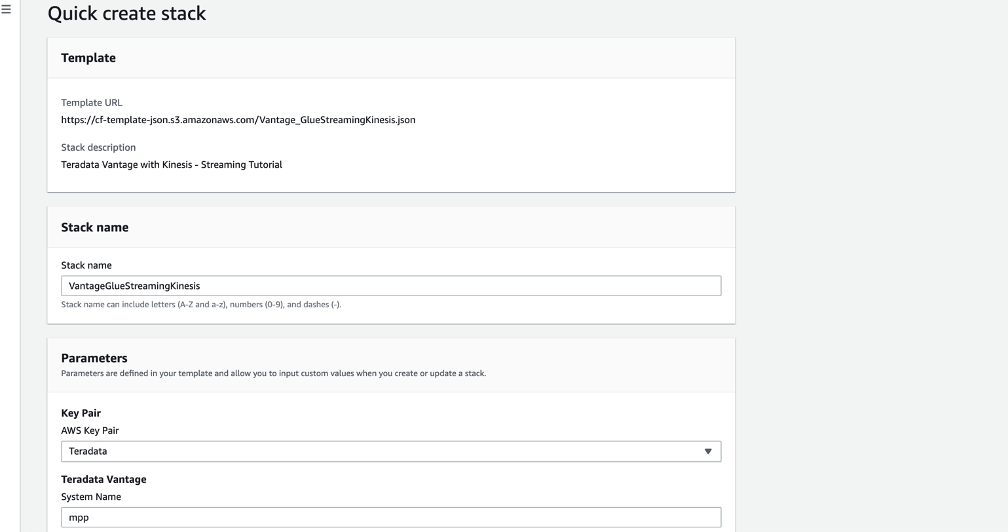
Once the CloudFormation console page populates the template URL, select AWS Key Pair [Teradata.pem as per prerequisites] from the dropdown.
As every other parameter is auto-populated for you, scroll down and acknowledge the IAM resource creation, check the tick box, and click ‘Create Stack’
.png?origin=fd "aws-glue-streaming-picture1-(2).png")
Teradata Vantage Developer Edition with all the required prerequisites including Kinesis Streams, Lambda functions, IAM roles, etc., will now be deployed into your account. This may take up to 20 minutes. Once the deployment is complete, navigate to the Stack Output tab and note down all the details listed there. You will need it for future steps.
Step 3: Create Amazon Kinesis Catalog Table in Glue
The below steps will take you through configurations which will help you to create Kinesis catalog tables to use as a source for the Glue Streaming ETL job.
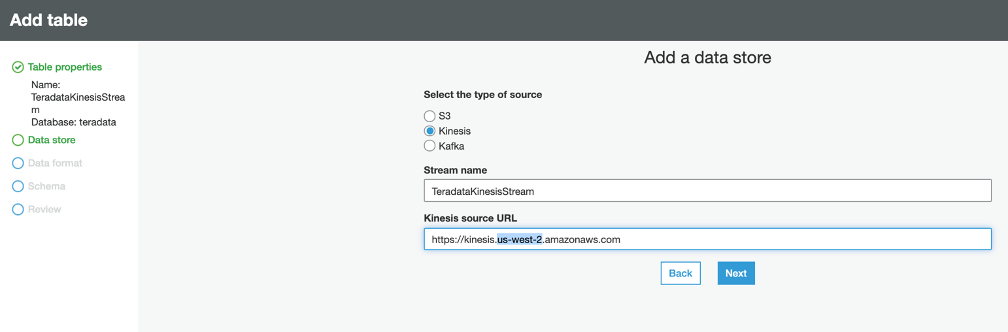
Let’s create a Glue Catalog table for Kinesis Stream. Click on Catalog ‘Tables’ and on the ‘Add Tables’ button, choose ‘Add Tables Manually’. On the next screen, provide the name ‘TeradataKinesisStream’. Choose a database from dropdown; if you don’t have a database created already, refer to Working with Glue Databases to create one. Click ‘Next’ on the ‘Add a Data store’ page, select the type of source as ‘Kinesis’, enter the Stream Name as ‘TeradataKinesisStream’ and Kinesis source URL as https://kinesis.${AWS::Region}.amazonaws.com. Replace ${AWS::Region} with your region. Click next to continue. (you may look at CloudFormation output section for same info)
.png?origin=fd "aws-glue-streaming-picture1-(3).png")
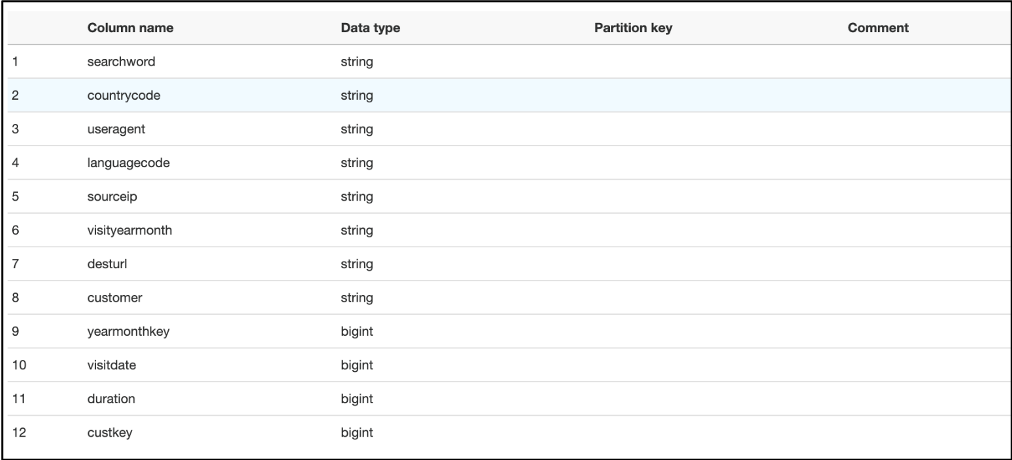
On the next page, select Classification as ‘JSON’ and click Next. In the define schema screen, click ‘Add Column’ and below column names with following types.
| Type | Column Name |
| String | searchword, countrycode, useragent,languagecode, sourceip, visityearmonth, desturl, customer |
| BigInt | yearmonthkey, visitdate, duration, custkey |
.png?origin=fd "aws-glue-streaming-picture1-(4).png")
Click next, review and click Finish on next screen to complete Kinesis table creation.
Step 4: Authoring a Glue Streaming ETL job to stream data from Kinesis into Vantage
Follow these steps to download the Teradata JDBC driver and load it into Amazon S3 into a location of your choice so you can use it in the Glue streaming ETL job to connect to your Vantage database.
- Download the latest Teradata JDBC driver.
- Uncompress tdjdcb4.jar from the downloaded file.
- Create an Amazon S3 bucket.
- Upload tdjdbc4.jar to the S3 bucket.
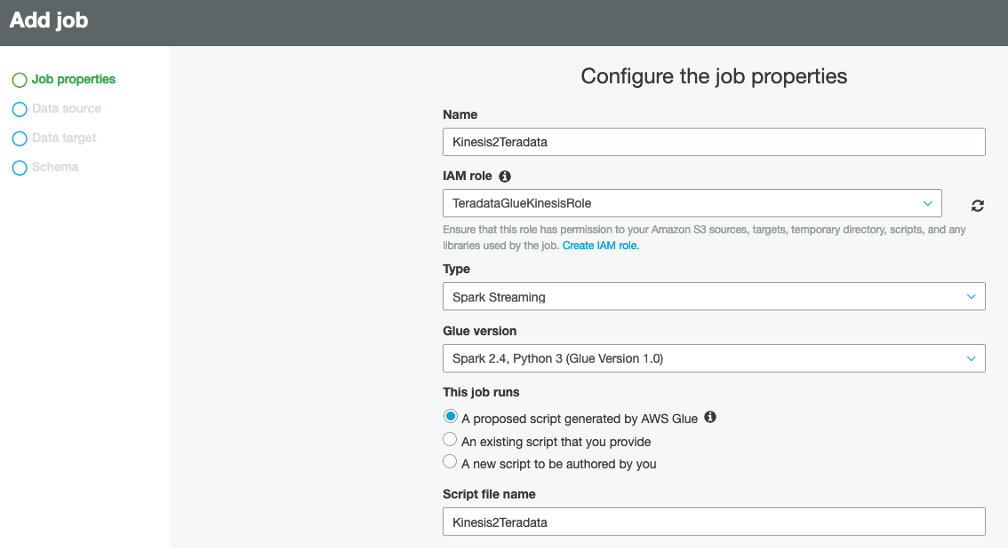
Now, let’s author a streaming ETL job from the AWS Glue ETL Jobs tab. From the left panel, click Jobs, and then click the ‘Add Job’ button. On the next page, provide ‘Name’ as ‘Kinesis2Teradata’, choose ‘IAM Role’ ‘TeradataGlueKinesisRole’ from the dropdown, select Type as ‘Spark Streaming’ and ‘This Job Runs’ as ‘Proposed Script generated by AWS Glue’. Leave everything else to default and scroll down.
.png?origin=fd "aws-glue-streaming-picture1-(5).png")
While in the same window, select ‘Security Configuration, script libraries, and job parameters (optional)’ to expand the section.
In the ‘Dependent jars path’ field, enter the path of the S3 bucket and key name of the Teradata JDBC driver. The format should be similar to: s3://<your-bucket-name>/terajdbc4.jar
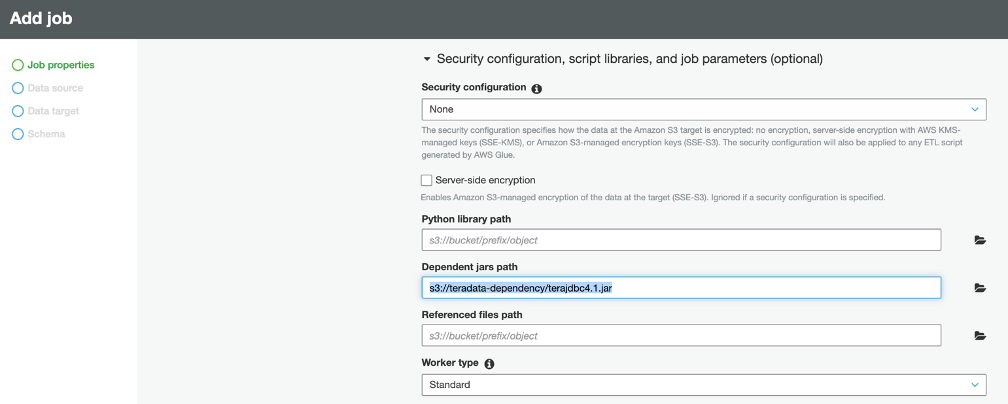.png?origin=fd "aws-glue-streaming-picture1-(10).png")
Leave the rest of the parameters at their default value, scroll down, and select Next.
The Data Source pane is displayed. Select the radio button for the table TeradataKinesisStream you created above and then click Next.
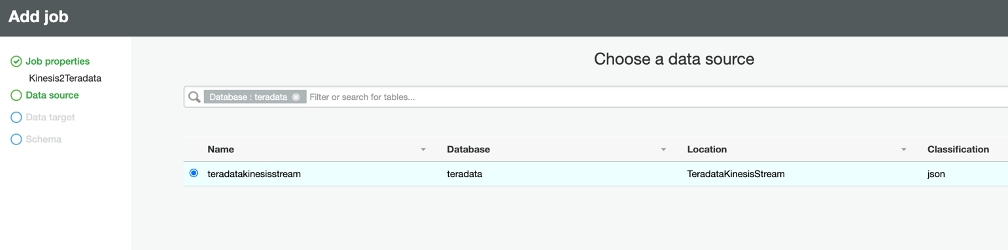.png?origin=fd "aws-glue-streaming-picture1-(11).png")
The Data Target pane appears. Select the same TeradataKinesisStream and then click Next. We will be changing the destination in the script instead.
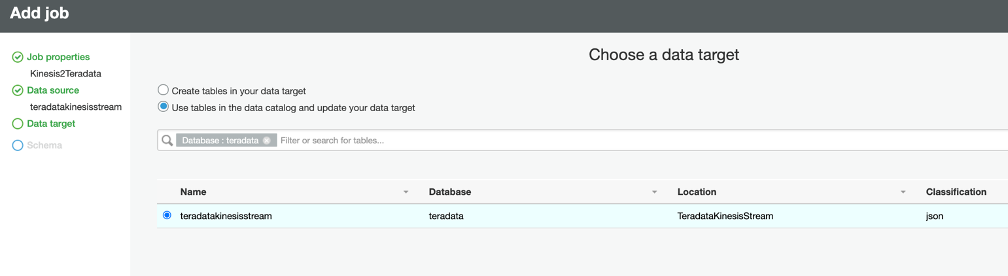.png?origin=fd "aws-glue-streaming-picture1-(12).png")
The next window displays the mapping of source columns to target columns. No changes are needed.
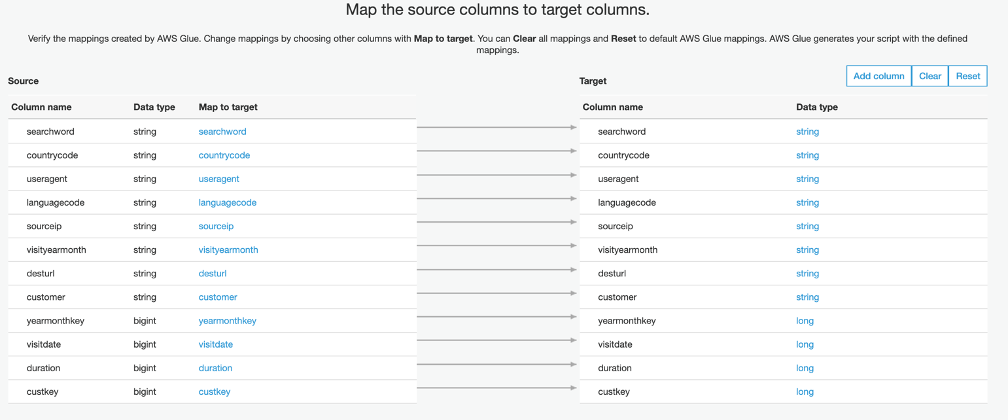.png?origin=fd "aws-glue-streaming-picture1-(13).png")
Click Save Job and edit script. Also make these changes to the script:
- On row 33, change windowSize from 100 seconds to 5 seconds
.png?origin=fd "aws-glue-streaming-picture1-(14).png")
- On row 32, delete the datasink1 row and add the below snippet with the details for the Teradata JDBC driver using these values, and ensure you update your vantage ip/hostname in this.

At the top of the page, select Save. Finally, select Run Job to begin stream data from Kinesis to Vantage. The job will take a few minutes to kickstart.
Step 5: Start Lambda Streaming Stimulator – Kinesis Producer
While the Glue job is running, let’s navigate back to the CloudFormation Resources page to find our Lambda Function name, or simply click on the TeradataStreamingStimulator Physical ID link to launch Lambda console.
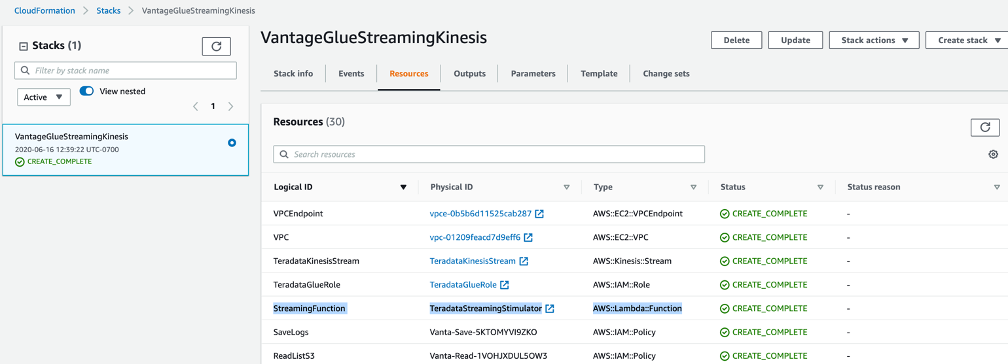.png?origin=fd "aws-glue-streaming-picture1-(15).png")
While in the Lambda console, click on the Test button on the top right corner to simulate streaming data.
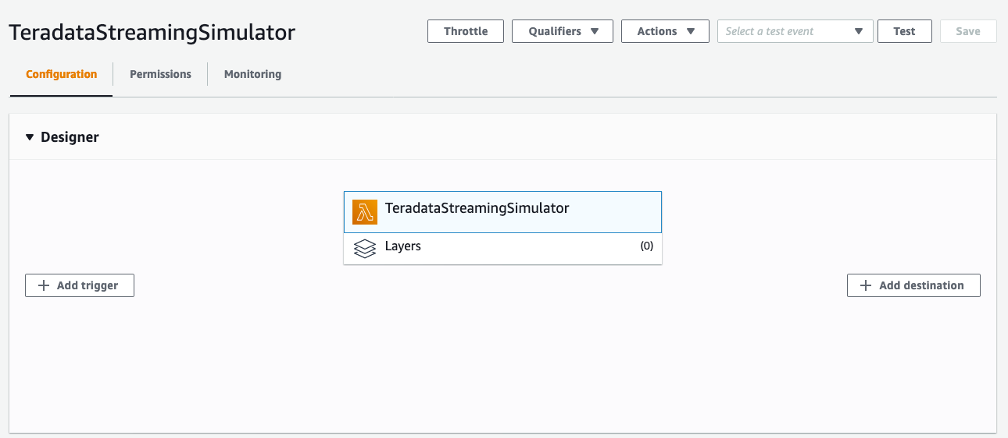.png?origin=fd "aws-glue-streaming-picture1-(16).png")
A ‘configure test event’ pop-up would appear. On the ‘configure test event’ pop-up, provide the json record shown below, which is formatted with fields listed for simulator to run. Provide a name for the test event and click Save to create test event.
| { "bucket": "streaming-data-repo", "stream_name": "TeradataKinesisStream" } |
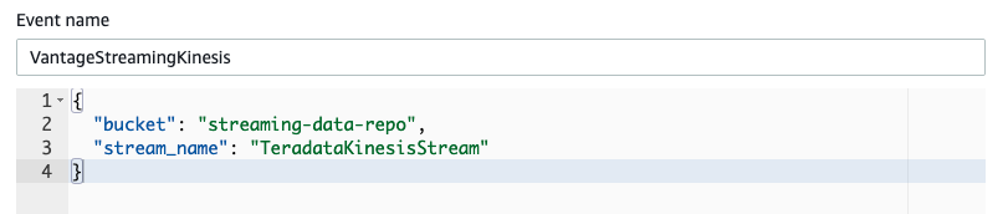.png?origin=fd "aws-glue-streaming-picture1-(17).png")
The bucket will have data to be streamed. Click Save. Once saved, click Test again to launch the simulator to stream data into the Kinesis Stream provided in the configuration. Once clicked the simulator will run for 2 minutes before it times out with an error. [Timeout can be adjusted in the lambda configuration from console itself. It is set to make sure streaming is stopped to avoid resource consumption.]
Step 6: Use Amazon QuickSight to Visualize Analyzed Data
You can apply numerous analytics on data loaded into Vantage. However, in this example we’ll continue to focus on demonstrating how to use QuickSight to visualize the data loaded into Vantage.
To get started, open Amazon QuickSight and create a new dataset. From the list of data sets, select Teradata. A pop-up window appears.
- In the Data Source Name field, enter the DNS name of the Vantage instance for the database server, as well as the port (1025) and database credentials from the database you created in Step 3.
- Select Validate Connection to check the correctness of the parameters. Once a connection is established and validated, a green tick symbol appears beside it.
- While in the same pop-up window, select Create Data Source.
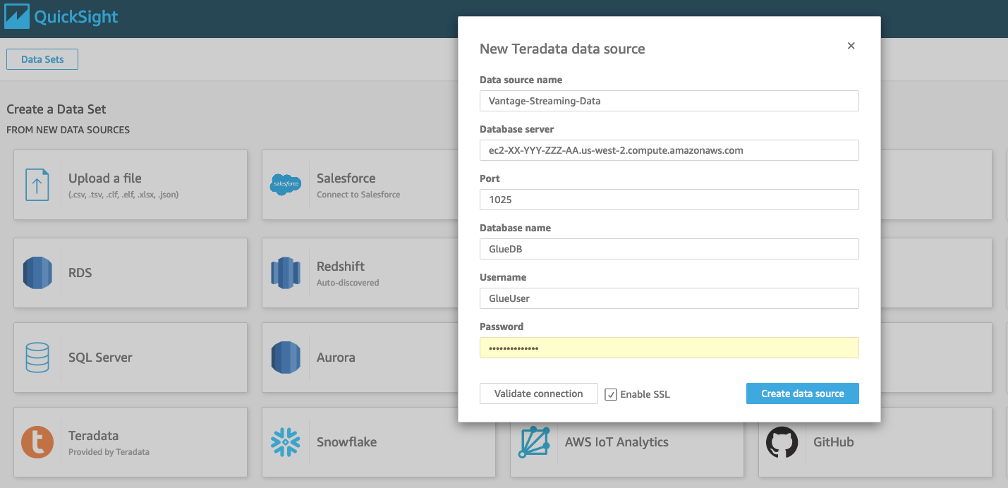.png?origin=fd "aws-glue-streaming-picture1-(18).png")
Once the data source is created, Amazon QuickSight will identify the tables in Vantage.
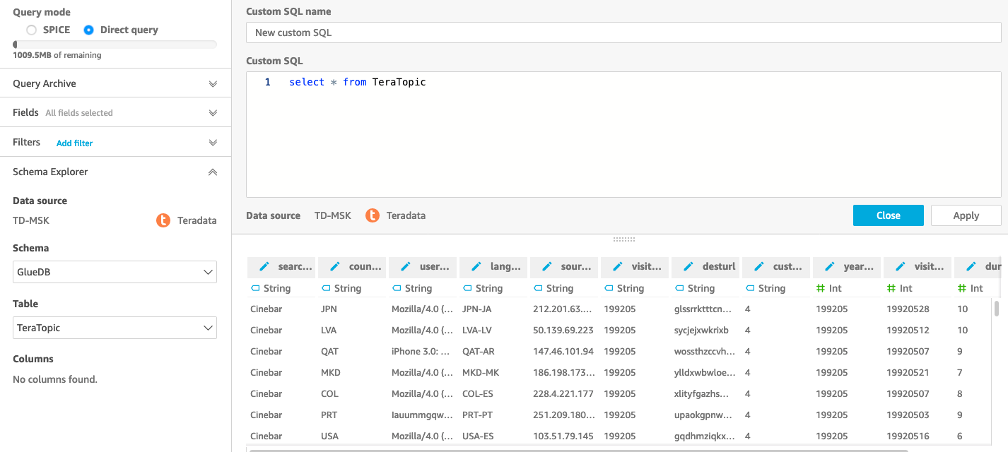
- From the Choose Your Table TeraTopic. From the pop-up window, select Use Custom SQL.
- Provide a name for the query and use ‘select * from TeraTopic’ as query, click ‘Confirm Query’. Once loaded click ‘Edit/Preview data’. It will load the data as below:
.png?origin=fd "aws-glue-streaming-picture1-(19).png")
- Change the data type of the Dates fields as required or you may create calculated fields to start visualizing the data using QuickSight.
To Learn more about creating an AutoGraph visualization in the Amazon QuickSight, see documentation.
Step 7: Cleanup
To avoid incurring additional charges caused by resources created as part of this post, make sure you delete the AWS CloudFormation stack. Go to the CloudFormation console and in Stacks you can delete the stack that was created. Also Stop the Glue Jobs created and delete connections, databases, tables and Glue jobs created.
Conclusion
In this blog we learned how to setup custom database connectors in AWS Glue, how to use Streaming ETL and seamlessly stream data from Amazon Kinesis to Teradata Vantage, and how to visualize the results directly using Amazon QuickSight.
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information.
AWS Glue streaming ETL makes it easy to set up continuous ingestion pipelines that prepare streaming data on the fly and make it available for analysis in seconds. Streaming ETL jobs in AWS Glue can consume data from streaming sources likes Amazon Kinesis and Apache Kafka, clean and transform those data streams in-flight, and continuously load the results into Amazon S3 data lakes, data warehouses, or other data stores.
Teradata Vantage provides an end-to-end, unified analytics platform for mission-critical workloads. It enables business leaders to shift focus from the mechanics of analytics to the meaning behind the data. Vantage on AWS is available in AWS Marketplace through both public and private listings.