
Historically, data governance has been a challenging topic of conversation for decision makers. Technologists have faced an uphill battle trying to engage business consumers to actively take ownership of “their” data.
Organizations require a huge cultural shift to move from a single integrated Data Warehouse to an analytic ecosystem optimized to deliver analytic results while minimizing complexity in the cloud and on-premises. The rush to enable advanced analytics without proper planning leads to new ways to duplicate, orphan and silo data.
The proliferation of multiple data platforms and shared responsibilities between IT and the Business requires a renewed focus on Data Governance that most organizations haven’t even contemplated.
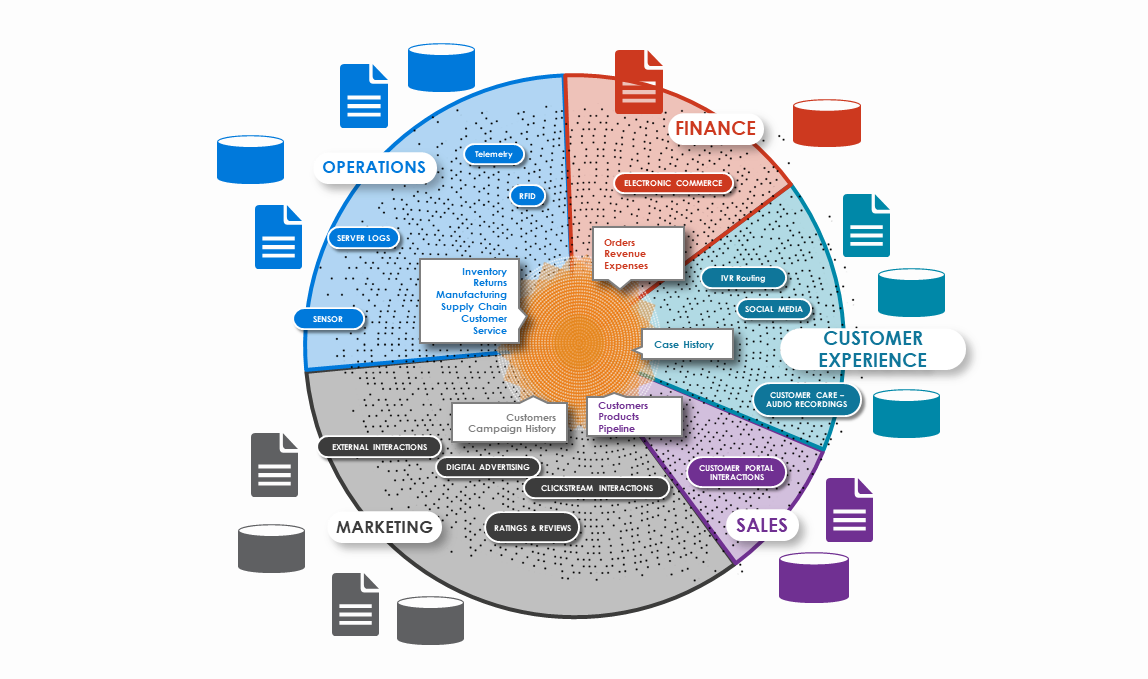
Figure 1. Tightly coupled data at the core of the Analytical Ecosystem digresses to loosely and non-coupled on the edge
What is the Cultural Shift?
Data scientists, business users, analysts and casual data consumers all want fast access to clean, related, pertinent, and timely data. Enabling and deploying new advanced analytics, machine and deep learning capabilities in a cost-effective manner across the entire analytical ecosystem places new demands on Business and IT. Explicitly, the shift is in who deploys data, where it is deployed, how tightly is it integrated, who provides business context and who governs what. That’s a lot of change from the days of a “Single Version of the Truth”.
Who deploys data?
This is the easy part. With the introduction of the Analytical Ecosystem, both IT and the Business have the ability to deploy data. But data deployed by IT and Business likely has very different lineage, provenance, and lifecycles. IT, you are still the owner of enterprise data (application sourced, trusted, transactional, and master data). It is IT's job to deploy that information in appropriate forms. Business, it is your job to integrate this data with our own sources, like external public domain data (weather) or purchased data (demographics/psychographics) in your sandboxes, lakes, etc…
Who governs what?
This is a bit more complex. If you guessed the group that ingested the data, then you would be partially correct. The business still owns all of Data Governance from a quality perspective. The Business also still owns the business-related metadata associated with enterprise data. But now the Business owns governing the business context (business and technical metadata) of the data they are ingesting to ensure that it can be integrated (if needed) with enterprise data. Did IT just shirk some of their responsibility? Not exactly, let’s discuss their new responsibilities next.
Where is data deployed?
This topic is actively debated in nearly all of my clients and across entire industries. Like the messaging coming from Hadoop vendors a few years ago, now Cloud vendors are advocating that all your data should be on their platform. Every time there is a new technology (and they are coming at us faster now), they have the same old one-liner, “All your data should be here”. Should your data be in a cloud vendor’s Data Lake? Yes, some of your data should absolutely be in the Data Lake (on-premises or in the cloud). Also, some of your data should also be in Sandboxes, Labs and Data Marts. Additionally, your clean, curated and trusted data should be in your Data Warehouse.
Most importantly, the platforms should be interconnected via a high speed fabric that enables physical and virtual projections. IT this is your new governance responsibility. Deploying centrally managed scalable data virtualization technologies enables sharing data at runtime without having to build complicated data synchronization processes. This has real business value for certain analytical use cases and should be deployed as a standard capability within your analytical ecosystem.
IT, it is also your responsibility to know where all the data is deployed, what the data’s technical metadata is, what the data’s lineage and provenance is, who is using the data, how the data is being used, and how frequently. Why? Because it is your responsibility to manage the overall cost to deploy and manage the Analytical Ecosystem. By enabling Self Service (including Data Ingestion) for the Business, you must take on new governance roles to ensure a fully functioning, self-provisioning and cost-effective environment.
Governing Data Across the Analytical Ecosystem
Technology Centric Responsibilities
- Know where all the data is – Start inventorying now. You have to get your arms around what is where before it spirals out of control and you are back to 100s of independent Data Marts.
- Step up your Metadata Management program. As you inventory all the data, ensure you have a repository to capture that information that can be share effectively with your business partners.
- Actively manage the lineage and provenance of data. All the data movement, loads and integration jobs need to be managed via an ABC (Audit, Balance & Control) framework to ensure you have the latest version of data in the Data Warehouse, Data Lake, Data Marts, Sandboxes, etc… This truth never goes out of style – Once you copy data it’s already stale. Make sure you know how stale and where it came from.
- Know who is using the data and how frequently they are accessing it. This is easy on the Teradata platform. You monitor who is logging in and what they are querying via DBQL. This is not as easy on other platforms. You will have to develop and deploy various monitoring methods ranging from fully automated to mostly manual to accomplish this.
- Consolidate duplicated data into the Warehouses and virtually project it back out to the Lake, Labs, Sandboxes and Marts via the Fabric. IT you own the costs associated with managing and deploying the Analytical Ecosystem. Storing once, reusing many times is still as true today as it was before.
Business Centric Responsibilities
- Communication – As IT enables self-service with greater autonomy and access to enterprise data than ever before, it is your job to be open and candid about what’s working and what’s not. What data are you ingesting and what do you want to manage and what do you want to outsource to IT? IT is a great resource to manage processes once they have been established.
- Business context – This has always been the responsibility of the business, but IT has soft-pedaled it for years. Be prepared to receive raw, un-curated data and get ready to roll up your sleeves to start cleaning up the data in the source systems. IT has been patching this data in data movement/integration jobs for years. There are some ugly data issues out there that you probably are not prepared for.
- Analytic projects – You probably don’t have all the skills you need to be self-sufficient. But you can build these skills and capabilities in-house over time. Reach out to IT for advice on who to bring in to temporarily augment your team. Get your people the training they need and work with experts.
- Operationalizing your solutions – I already mentioned that IT is a great resource for managing established processes. Don’t burden your business team with managing load jobs, data cleansing jobs, maintaining models, etc. Those are great opportunities to outsource to IT’s partners that they buy in bulk. IT can buy additional operational support management at a much lower cost than you can buy one resource at a time.
Un-curated, duplicated, stale data will be the biggest long-term cost driver across the Analytical Ecosystem. How do I know? Remember when we consolidated all those independent Data Marts into the Data Warehouse because it cost a fortune to run 20 different technologies and to keep them all in sync and reconciled? Today the new Analytical Ecosystem introduces the same problem at a larger scale, but the above strategies can help your organization mitigate and manage your environment to ensure you able to take full advantage of your company’s Analytical Ecosystem.