
Every company struggles with data not maintained by traditional transactional systems (ERP, EHR, billing/accounting, etc.). Within these companies, spreadsheets (Excel) become the de facto tool to maintain and store “orphan data.” Orphan data can have different meanings; however, in this case, orphan data refers to data that has no home in a transactional system but is critical to running the business. Sometimes, this orphan data is termed “User Managed Data.” Here are some real-world examples of orphan data:
- A major retailer uses Excel to maintain details for store space in support of 3rd party stores within stores (i.e., Starbucks and McDonalds inside a big box retail store). This data must be completed by each store or region manager and updated by the end of each month to complete the period close process. Spreadsheets are stored on SharePoint/Teams and then transmitted to the analytical platform via FTP/ETL. Errors are common and often only noticed by anomalies in final reports. Supporting the period close in a timely fashion becomes a major challenge.
- An online pharmacy leverages Excel to maintain information on available drugs, alternates, and past/future pricing. The spreadsheets contain hundreds of rules and validations. Parts of this data set must be uploaded to an enterprise data store for BI and analytics.
- An agrochemical biotech manufacturer uses Excel for maintaining current and planning future sales organization structures. In this scenario, the spreadsheets are complex and require data from ERP and data warehouse systems to calculate commissions, balance future sales coverage with similar revenue, costs, miles/territory coverage, and so on. The process is iterative and requires up to six months to complete. Many departments and teams participate in the overall process and must sign-off/approve the changes.
- Another large manufacturer struggles to tag data. For instance, they need to identify all the customers and/or products exposed to a particular promotion. Users search, filter, and download customer or product data to Excel. Then, users add attributes to designate if a product or customer has leveraged a promotion. They repeat the process for similar requests. As a result, Excel spreadsheets are everywhere, and tribal knowledge of the spreadsheet universe is essential.
Each of these scenarios is critical to enabling core business processes and driving business decisions. None of these examples belong in any one ERP, EHR, billing, or other transactional system, nor do they justify the effort and cost to customize these systems. Without this Excel-based data, these companies could not close period-end financials, pay their sales team, provide pricing info to customers, or organize a sales team for optimal performance. Furthermore, business users increasingly demand ways to quickly make changes without requiring an “IT project” for every change. Today, companies want to be agile and proactive. They need to capitalize on the tools, technologies, and deep analytics available. Business as usual is not good enough anymore.
Simply put, orphan data is often the root cause of many company’s struggles to enable more efficient core business processes. The following list represents some of the challenges associated with enabling more efficient orphan data:
- lack of compliance
- security
- governance
- data quality issues
- scale/performance
- lineage/audit history
- collaboration issues
- ease and speed of making changes, by the data and process owners
Some good news exists! Tools have evolved to meet some of the challenges. Let’s examine some of the common tools being used by organizations, and what to look for.
Over the past decade, tools like SharePoint, Teams, and others have provided an easier way to store and access orphan data, but they only solve the issue of storage and access. The data stored in SharePoint/Teams needs to be transferred/moved on a regular basis to a location of wider access. That often means data movement to an Enterprise Data Warehouse (EDW), Data Lake, Object Store, etc. This data must be made available to enterprise reports, analytic models, and other planning applications. As a result, the issues of compliance, security, governance, data quality, lineage, and scale remain.
To address these other challenges, let’s examine some other options. This list contains the key capabilities to look for when evaluating tools:
- A web-based tool with a good end-user experience. The browser-based capability negates the need to have end users install or maintain any client level details. As well, a web-based tool can be more easily extended externally to key partners, customers, or vendors.
- Ability to support easy download and upload via Excel, as users have grown comfortable using Excel.
- Data quality enforcement with a business rules engine and the option to configure rules without coding.
- Works directly on the data store of choice to minimize/eliminate any data movement. (And remember, changes at the speed of business is the goal. If the tool can communicate with multiple data stores, that’s a bonus.)
- Self-service tool that is easy to configure, but flexible enough to support your organization’s specific processes and needs when required.
- Provide strong approvals and workflow capabilities that can be configured by non-technical business users.
- Provide strong access control and security, with the ability to integrate to your organization’s authentication tools.
- Provide audit tracking and history (who changed, what changed, why changed, etc.)
- Easy to configure structure changes for data (change/add attributes, tables, views, UI’s, etc.)
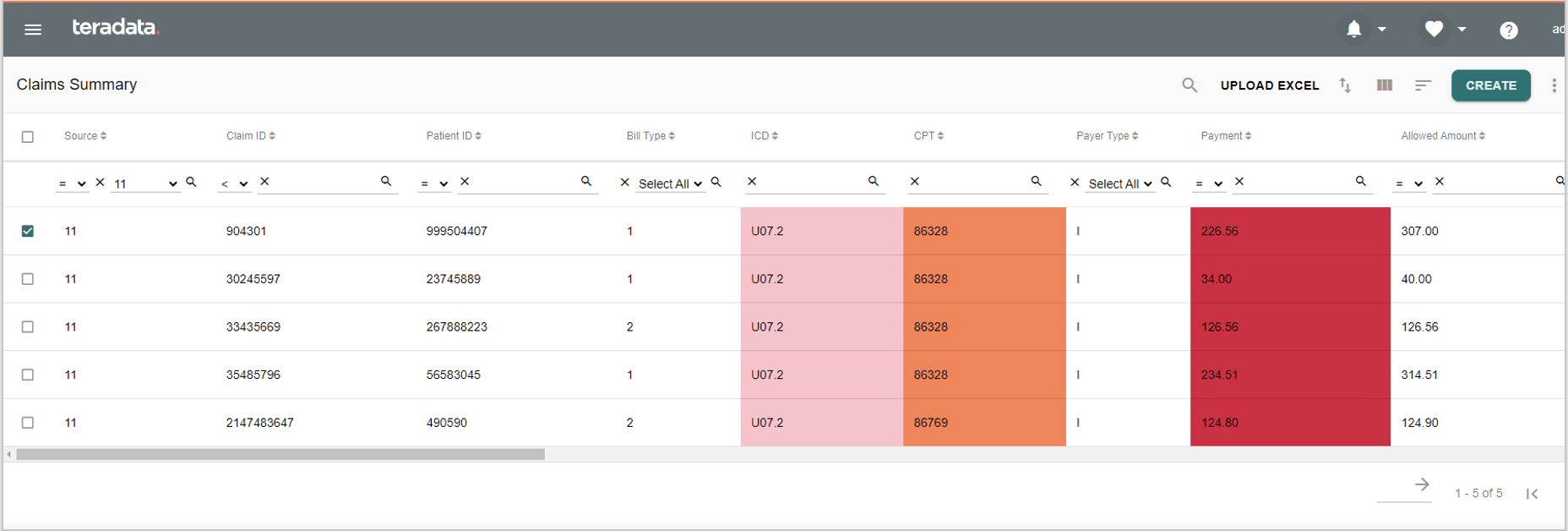
- Teradata’s Reference Data Manager (RDM) satisfies all the listed capabilities. Teradata released one of the industry’s first RDM solutions over a decade ago. While other RDM tools may focus exclusively on managing codes and relationships, Teradata leverages basic code and relationship management capability to deliver wider data management capabilities. For instance, Teradata RDM automatically generates data maintenance UIs and web services for any data table. An example of the auto generated web UI is displayed below. Additionally, Teradata RDM can quickly convert a spreadsheet into a table.
.png?origin=fd "Screen-Shot-2021-09-27-at-9-12-08-AM-(1).png")
For each of the business use case scenarios listed in the first section, Teradata RDM quickly solved the challenges of orphan data. The below steps were followed:
- Model each scenario as a collection of tables, views, etc. These tables/views looked very similar to the original Excel spreadsheets.
- Leverage the reference data self-service tool (RDM) that auto-generates web UIs for each table. The web UI supports table maintenance without code and the upload/download via Excel. The Excel upload process supports data quality enforcement (both data model and application-level business rules).
- Attributes that require quality checks are isolated and determined if data model logic could enforce quality or if other rules/logic were required (i.e., data type enforcement or valid value list enforcement).
- Business rules (typically SQL) were defined for the non-data model rules (valid ranges, tolerances, etc.). Teradata RDM provides a business rules wizard that creates SQL rules without coding.
- Data ownership for each attribute was identified and incorporated into the role-based access control. The self-service tool supports granular role-based access to the level of row and column (cell) intersection.
- Six months after deployment, 90% of the users from the above examples were no longer using Excel to make most updates. The 10% exceptions were still using Excel for bulk data uploads.
Overall, orphan data challenges can be daunting. However, when you combine the right process and technologies, the solution becomes straightforward.