
In the quest to turn mountains of data into useful—and actionable—information, many companies struggle to establish a repeatable process that leverages architecture layers while avoiding analytical anarchy.
Too often the solution is to think of the problem in silos and vertical solutions—to see the world of operationalized analytics as different from the arena of data exploration and data science. Of course, there is a core relationship between the two as the biggest value comes from first finding the insight and then operationalizing it across the company.
The good news is that we have not forgotten the lessons learned. We have seen a variation of this problem before and we conquered it. We understand what it takes to build a complete environment to serve the broader audience and purpose.
The current analytic dilemma is analogous to the data problem in the early eighties. Back then, people had a challenging time trying to store and analyze large volumes of data due to limits of technology. The conventional wisdom was to push data to functional data silos and “data marts” that would allow individuals to run their own processes without having to worry about scaling to an enterprise level.
Too often the solution is to think of the problem in silos and vertical solutions—to see the world of operationalized analytics as different from the arena of data exploration and data science. Of course, there is a core relationship between the two as the biggest value comes from first finding the insight and then operationalizing it across the company.
We’ve seen this problem before….
Oliver Ratzesberger, COO of Teradata, recently made the observation,”The industry has ‘unlearned’ a lot of what it had learned in the past.”The good news is that we have not forgotten the lessons learned. We have seen a variation of this problem before and we conquered it. We understand what it takes to build a complete environment to serve the broader audience and purpose.
The current analytic dilemma is analogous to the data problem in the early eighties. Back then, people had a challenging time trying to store and analyze large volumes of data due to limits of technology. The conventional wisdom was to push data to functional data silos and “data marts” that would allow individuals to run their own processes without having to worry about scaling to an enterprise level.
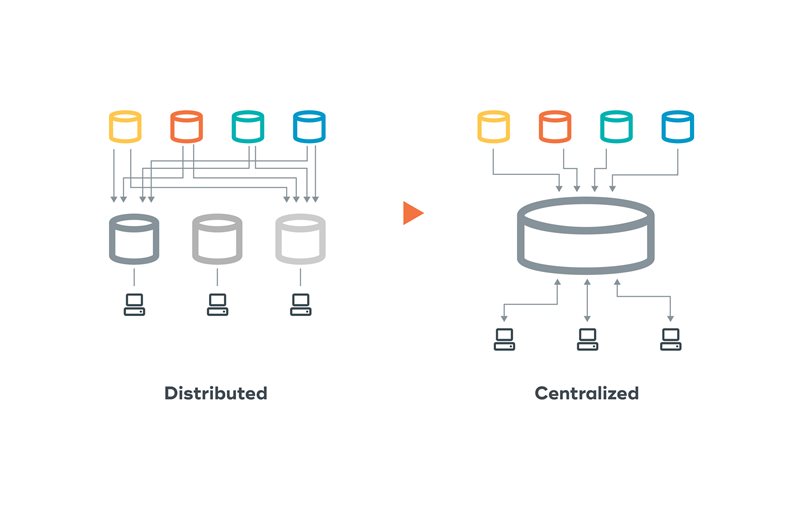
A second hurdle was that the mainframe (for the younger crowd - look it up), and the databases of the day, were really for transaction processing—not analytics. Trying to run analytics on the same platform as the transactional processing could impact service level agreements and interfere with production workloads. So again, it was easier to circumvent the problem and just build point solutions around the function. Get the data from wherever, store and manage for your purpose, and move on.
The Teradata Database was designed to effectively manage data at scale to enable enterprise analytics. We solved the technical issues and showed that by integrating the data in a relationship model we could allow any question at any time for any function. We solved the problem by understanding that silos do not create integration nor do they provide a full view of the business.
Silos are back, but with an analytics twist….
Let’s jump to today and a variation of the situation we originally saw in the early days. Today, the “data warehouse” has gone from being the platform to drive exploration and analytics to an environment running mission critical operational reports and analysis. Some companies are running 10s of millions of queries per day and the business relies on consistency and performance to meet SLAs.In short, the data warehouse has become a protected species. When companies want to extend the user community to include data scientists and business analysts who need to do some new investigation and innovation, they are taking the path of least resistance and creating analytic silos. The twist is that there are now many more tools and functions that are being brought to bear in these processes so people are now creating “analytic silos.”
For example, we may have an analyst using SQL to create a small database to ingest new data and combine it with some data pulled from the data warehouse or other production systems. We also have different data scientists, each with his or her preference for language and tools. Some like R, others want Python, some want to use SAS, and the list just keeps growing. Everyone wants to use the tools they are comfortable with to run a particular function.
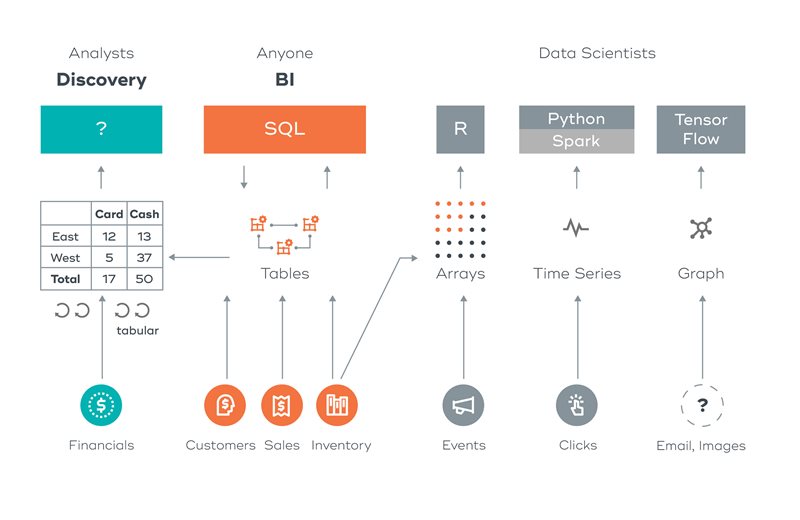
BUT… they all need to analyze the data, and now that is everywhere. Some data is in the warehouse, other data is in S3, Blob storage, or HDFS. We are again facing the situation that people turn to silos as the solution because they are not aware of the long-term pain associated with the short term gain (which happens to be the title of one of my first white papers, some 25+ years ago). The majority of time is spent unproductively moving and re-modeling data for analytic process.
Think horizontally, not vertically
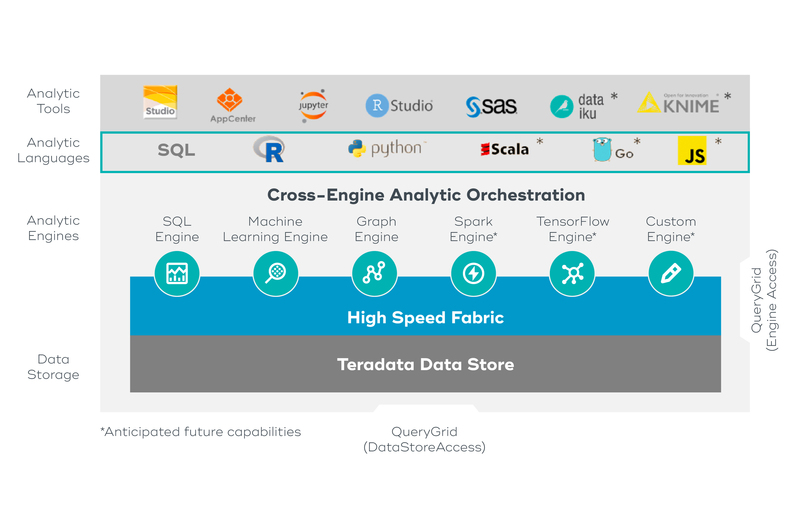
Tip of the hat to Wayne Dyer who said when you “change the way you look at things, the things you look at change.” Given our experience and understanding of the past, we are ready for the future. Rather than thinking in silos, we turned our heads and looked at the tiers necessary to drive this expanded world of data and analytics to solve the problem.The first realization was that we needed to expand the types of analytic engines within the larger environment. These engines and functions are used across a wide variety of use cases and rather than constantly replicating the functions (and hope they work the same in various places), it is much better to bring the engines into a logically central architecture and let them be called when necessary.
To that end, Teradata extended from just having a SQL Analytic Engine (i.e the Teradata Database) to including Machine Learning and Graph engines, with more to be added in the future. Now all types of programmers can simply reference the engine and function they need. This minimizes cost and data movement as well as improves consistency and performance. A win-win for all.
The second part is that we had to enable the engines access to not only much larger, but also much more diverse, sets of data, and not all that data will be suitable for relational database storage. So again, we provide the necessary connectivity across the data storage environments. Some data will be repeatedly used and have structure and good governance. Some data will simply need to be quickly stored, have unknown or variable structure, and have access by a limited number of people (maybe even just 1 person!).
The final integration point was the tools and languages out in the user community. The easiest way to kill any analytic system is to limit the tools that can access the platform. Again, we saw this before with all the SQL-based BI tools in the early 90’s. The tool choice should not limit access, thus we simply had a standard interface (SQL) to the data and let the user choose among the wide array of tool options. Today, the tools have exploded and include many more languages than just SQL. Teradata has abstracted the tools and languages, so any programmer can write in the tool of choice and still leverage the data and analytic engines. This drives more insights from the data, at a lower cost, and faster time to explore and develop new capabilities.
Teradata Vantage: Integrating analytics for greater outcomes
Long ago, we learned that integrating data is the key to increasing business understanding and better actionable insights—and that lesson is true as well for analytics.A final analogy: In today’s day and age, you do not want a separate device for e-mail, music, navigation, photos, gaming, and web searches. You want to have a platform that integrates all this capability, and is ready to absorb new capabilities and applications, as quickly as they are developed.
You should demand the same of your business analytics environment – Welcome to Teradata Vantage, the platform for pervasive data intelligence.
Vantage allows enterprises to uncover actionable answers to the toughest business questions by tightly integrating the best analytic functions and engines to provide a scalable, agile platform that enables organizations to drive business value. It also provides access to a wide variety of descriptive, predictive and prescriptive analytics; autonomous decision making; machine learning functions; visualization tools and more, deployed across public clouds, on-premises, on optimized or commodity infrastructure, or as-aservice.
Users can also access and analyze all their data without having to learn a new tool or language, or worry about where data is located. This streamlined access is bolstered by Vantage’s integration with popular third-party tools and analytic languages, meeting users where they are and allowing them to work in the environments they already know best.
We all know that the future will come with a lot of change. Vantage is ready for that change, and it also allows you to increase that rate of change. It provides the architecture to quickly adopt new tools, languages, engines and storage into a scalable framework. One that provides the accessibility, auditability, and integration to enable your business answers—from innovation to full deployment and accelerate your outcomes!
Read more about Teradata Vantage here.